SMW教程第四章:语义化Wiki下知识图谱的概念与本体构建
一、知识图谱基础 (阅读并理解)
1、知识图谱基本概念
知识图谱是由 Google 公司在2012年提出来的一个新的概念。从学术的角度,我们可以对知识图谱给一个这样的定义:“知识图谱本质上是语义网络 (Semantic Network) 的知识库”。但这有点抽象,所以换个角度,从实际应用的角度出发其实可以简单地把知识图谱理解成多关系图 (Multi-relational Graph)。
那什么叫多关系图呢?学过数据结构的都应该知道什么是图 (Graph)。图是由节点 (Vertex) 和边 (Edge) 来构成,但这些图通常只包含一种类型的节点和边。但相反,多关系图一般包含多种类型的节点和多种类型的边。比如左下图表示一个经典的图结构,右边的图则表示多关系图,因为图里包含了多种类型的节点和边。这些类型由不同的颜色来标记。
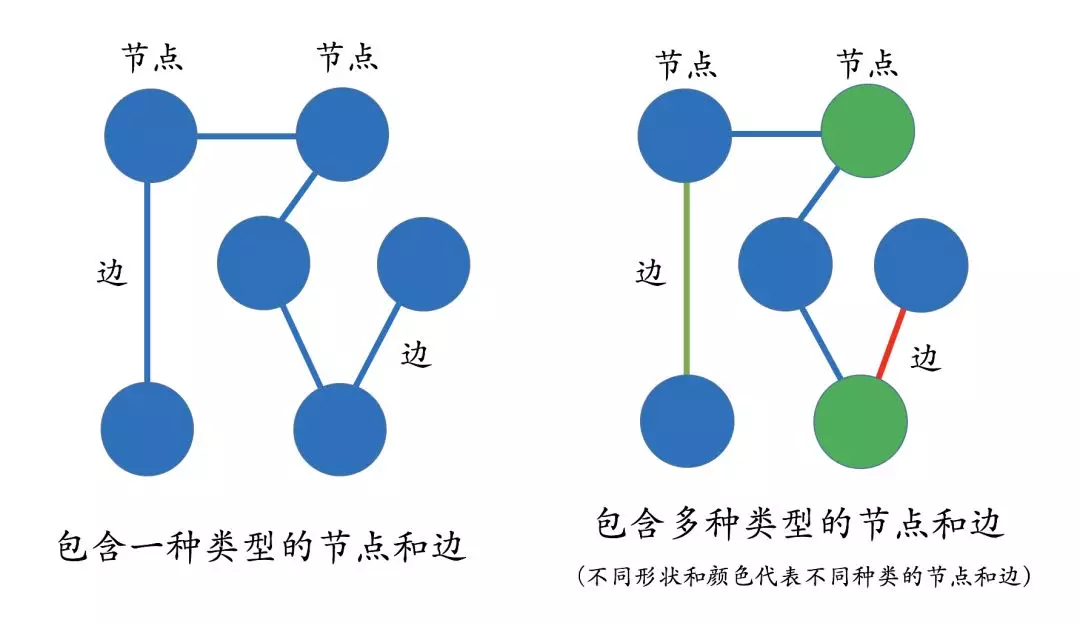
在知识图谱里,我们通常用 “实体 (Entity)” 来表达图里的节点、用 “关系 (Relation)” 来表达图里的 “边”。实体指的是现实世界中的事物比如人、地名、概念、药物、公司等,关系则用来**表达不同实体之间的某种联系,**比如人-“居住在”-北京、张三和李四是 “朋友”、逻辑回归是深度学习的 “先导知识” 等等。
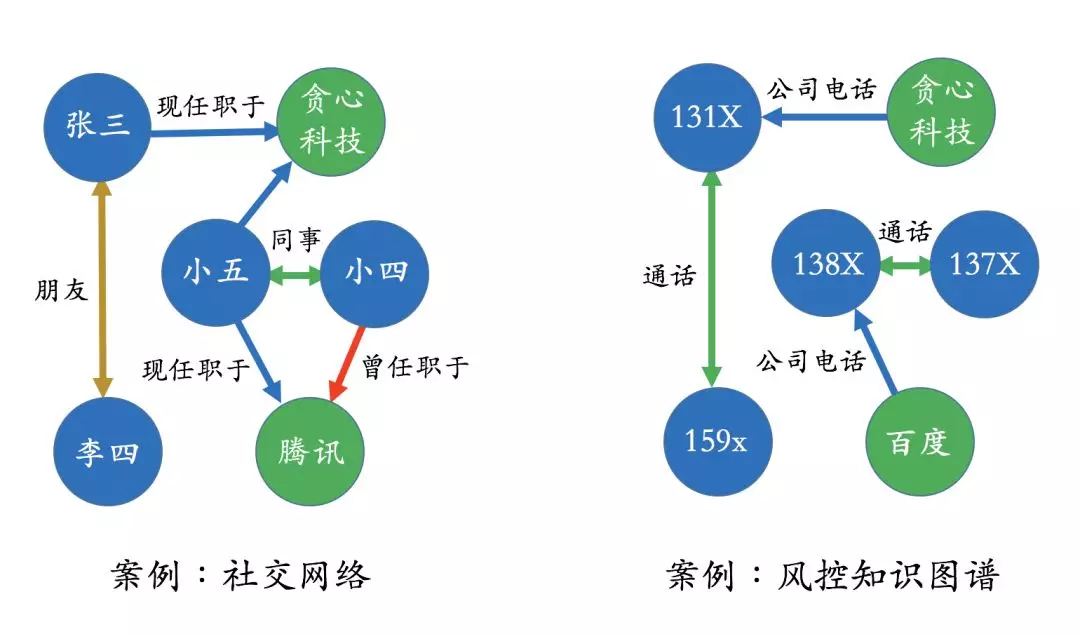
现实世界中的很多场景非常适合用知识图谱来表达。比如一个社交网络图谱里,我们既可以有 “人” 的实体,也可以包含 “公司” 实体。人和人之间的关系可以是 “朋友”,也可以是 “同事” 关系。人和公司之间的关系可以是 “现任职” 或者 “曾任职” 的关系。类似的,一个风控知识图谱可以包含 “电话”、“公司” 的实体,电话和电话之间的关系可以是 “通话” 关系,而且每个公司它也会有固定的电话。
2、知识图谱分类
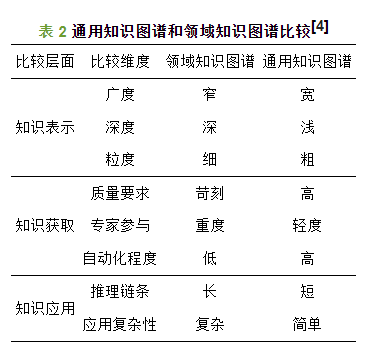
知识图谱分为通用知识图谱与行业知识图谱两类。这两种知识图谱主要存在覆盖范围和使用方式上的差异。
- 大而全:通用知识图谱面向通用领域,主要包含了大量的现实世界中的常识性知识,覆盖面广。
- 小而精:行业知识图谱又称为领域知识图谱或垂直知识图谱,是面向某一特定领域的,是由该领域的专业数据构成的行业知识库,因其基于行业数据构建,有着严格而丰富的数据模式,所以对该领域知识的深度、知识准确性有着更高的要求。
我们在本课程中主要目的是构建一个小而精的行业知识图谱。
3、知识图谱的组成与架构
3.1 基本组成要素
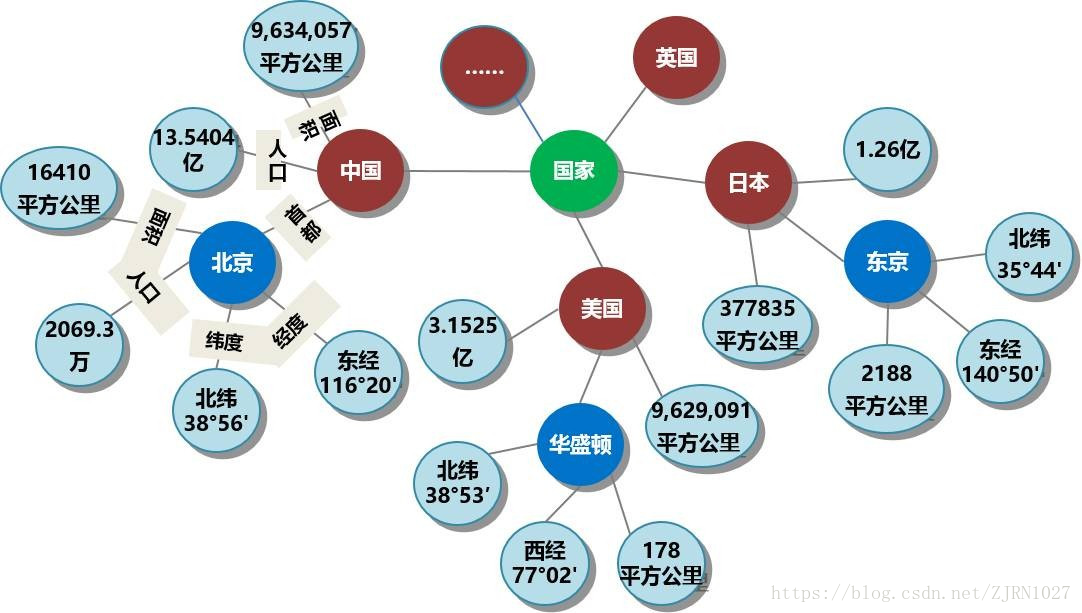
以上图的知识图谱为例,我们来介绍知识图谱的基本组成要素:实体、关系、属性、属性值、本体。
-
实体:是一个节点,它指的是具有可区别性且独立存在的某种事物。如某一个人、某一个城市、某一种植物等、某一种商品等等。世界万物由具体事物组成,此指实体,如图的 “中国”、“美国”、“日本”、”北京 “等节点。实体是知识图谱中的最基本元素,不同的实体间存在不同的关系,例如**” 中国”的首都是 “北京”**。
-
关系:是一条边,它连接了不同的实体,指代实体之间的联系,如图中的边 “首都”。关系是一种表示实体之间的逻辑关系的方式,用于连接实体并表示它们的相互关系。例如,在人与人之间的关系中,“朋友” 可以作为一种关系。关系可以是单向的 (例如 “父亲” 与 “儿子”) 或双向的 (例如 “夫妻”)。通过建模实体之间的关系,知识图谱可以帮助我们更好地理解实体之间的关系,从而更好地使用知识。
-
属性:是一条边,它指的一种实体的特征或描述性信息。如从 “北京” 节点指向 “16410 平方公里” 节点的边 “面积”。它是一种关于实体的附加信息,描述了该实体的特征,性质,状态等。例如,一个人的属性可以包括姓名,年龄,性别,职业等。属性可以是定性的 (例如性别) 或定量的 (例如年龄)。知识图谱的目的之一是通过建模实体的属性,使知识能够被机器理解和使用。另外,不同的属性类型对应于知识图谱上不同类型的边,如图上所示的 “面积”、“人口” 是几种不同的属性。在某种意义上讲,关系也是一种特殊的属性。
-
属性值:是一个节点,它主要指实体的某个属性的值,用来具体描述一个实体本身所具有的某种性质或特性,例如 “960 万平方公里” 等。
-
本体 (语义类、概念):是一个节点,这是一种特殊的实体,它是具有同种特性的实体构成的集合,主要用来描述集合、类别、对象类型或事物的种类,如 “国家 “、” 民族 “、” 书籍 “、” 电脑 “等。本体与实体之间具有从属关系,比如图中的红色节点中国、美国、日本、英国属于绿色节点” 国家 “。本体规定了:
- 本体对应的实体应当具有哪些关系和属性,比如”国家 “应当具有” 面积 “属性,” 人口 “属性等。
- 本体所具有的关系和属性的约束。比如:
- “人口” 属性的属性值必须是数字。
- “首都” 关系对应的实体,必须属于 “城市” 这一本体。
3.2 基本单位
而构成知识图谱的基本单位是 “三元组”,分为以下两种:
- (实体)-[关系]-(实体) 三元组:用来描述实体之间的关系;例如图中的 (中国)-[首都]-(北京)
- (实体)-[属性]-(属性值) 三元组:用来描述实体本身具有的特征;例如途中的 (北京)-[面积]-(16410 平方公里)
3.3 层次架构
而在知识图谱的层次关系上,我们给出以下示例来解释:
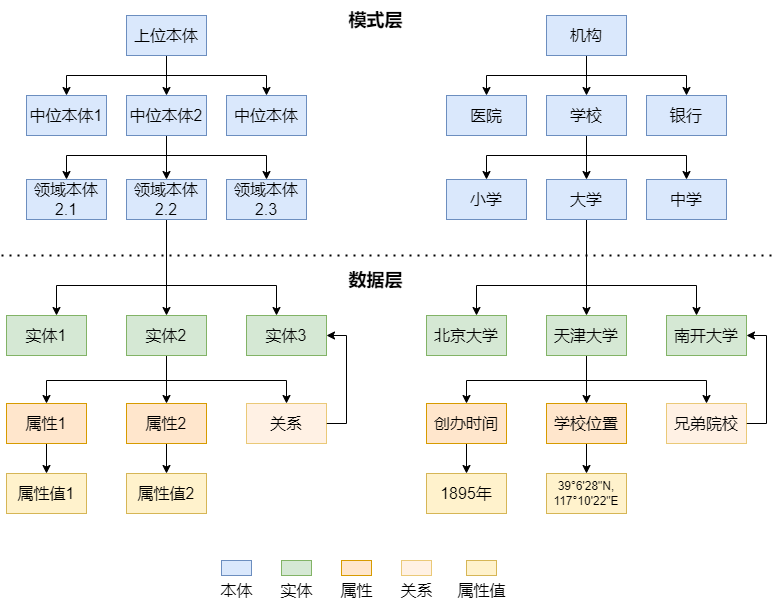
注意,该图是一个简化的图例,并不是一个严格的知识图谱。我们在该图中将”属性 “单独抽出来,来强调说明知识图谱中各个组成要素的层次关系。可以看到,从该图中从上到下,术语层次越具体。整体而言,我们可以将知识图谱纵向划分为模式层的概念图谱,与数据层的实体图谱。
-
模式层:是知识图谱的概念模型和逻辑基础,对数据层进行规范约束。多采用本体作为知识图谱的模式层,借助本体定义的规则和公理约束知识图谱的数据层。也可将知识图谱视为实例化了的本体,知识图谱的数据层是本体的实例。在知识图谱的模式层,节点表示本体概念,边表示概念间的关系。不同概念层级的本体之间具有上下位关系。如”机构 “是” 学校 “的上位本体,“学校” 是 “机构” 的下位本体。
-
数据层,事实以 “实体-关系-实体” 或 “实体-属性-属性值” 的三元组存储,形成一个图状知识库。其中,实体是知识图谱的基本元素,指具体的人名、组织机构名、地名、日期、时间等。关系是两个实体之间的语义关系,是模式层所定义关系的实例。属性是对实体的说明,是实体与属性值之间的映射关系。属性可视为实体与属性值之间的 hasValue 关系,从而也转化为以 “实体-关系-实体” 的三元组存储。在知识图谱的数据层,节点表示实体,边表示实体间关系或实体的属性。
一般而言,我们在知识图谱的实际应用中使用的绝大多数是数据层,如问答、推理、推荐等;而模式层往往非常简单,但它高于数据层,规定了数据层的知识图谱的表现形式。因此,对于模式层的定义非常重要。模式层的定义方法 (又称本体构建或 Schema 设计) 上,有两种方向:
- 自顶向下,利用领域知识或专家知识手工定义本体概念层次,以及本体的属性及本体间关系。
- 自底向上,借助一定的技术手段,从公开采集的数据中提取出资源模式,选择其中置信度较高的信息,加入到知识库中。这个过程往往是自动化或半自动化的。
3、知识图谱的构建方案
对于知识图谱的构建方法主要有自顶向下的构建方法和自底向上的构建方法。其主要区别在于模式层的定义上。
3.1 自顶向下
自顶向下的方法是指首先为知识图谱定义本体或进行 Schema 设计,包括本体的上下位关系和本体的约束等,然后逐步细化构建实体;常用于行业知识图谱。
在自顶向下的构建方案中,本体构建技术:常常采用 Protege 软件进行本体设计;或者使用传统关系型数据库的 UML 设计,再转化为图谱化的本体 Schema。手工方式对于通用知识图谱来说工作量巨大。
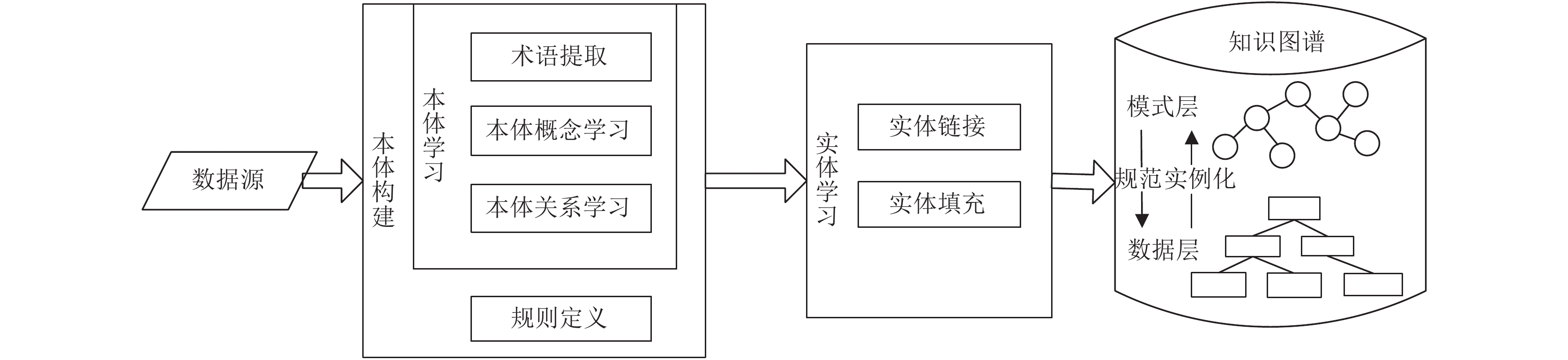
3.2 自底向上
自底向上的方法是指首先构建实体,然后通过实体相似度计算等方式,逐步往上抽象形成本体。自底向上的构建方法一般是从开放链接的数据源中提取实体、属性和关系,加入到知识图谱的数据层;然后将这些知识要素进行归纳组织,逐步往上抽象为本体或概念,最后形成模式层。常用于通用知识图谱。
在自底向上的构建方案中,本体构建技术:常常通过 NLP 技术和数据分析自动抽取文本中的领域实体和关系,通过聚类等分析方法自动构建领域概念的体系。但自动抽取的概念粒度过细,无法建立精确的概念层次及属性/关系约束。并不适合要求精确深入的行业知识图谱。
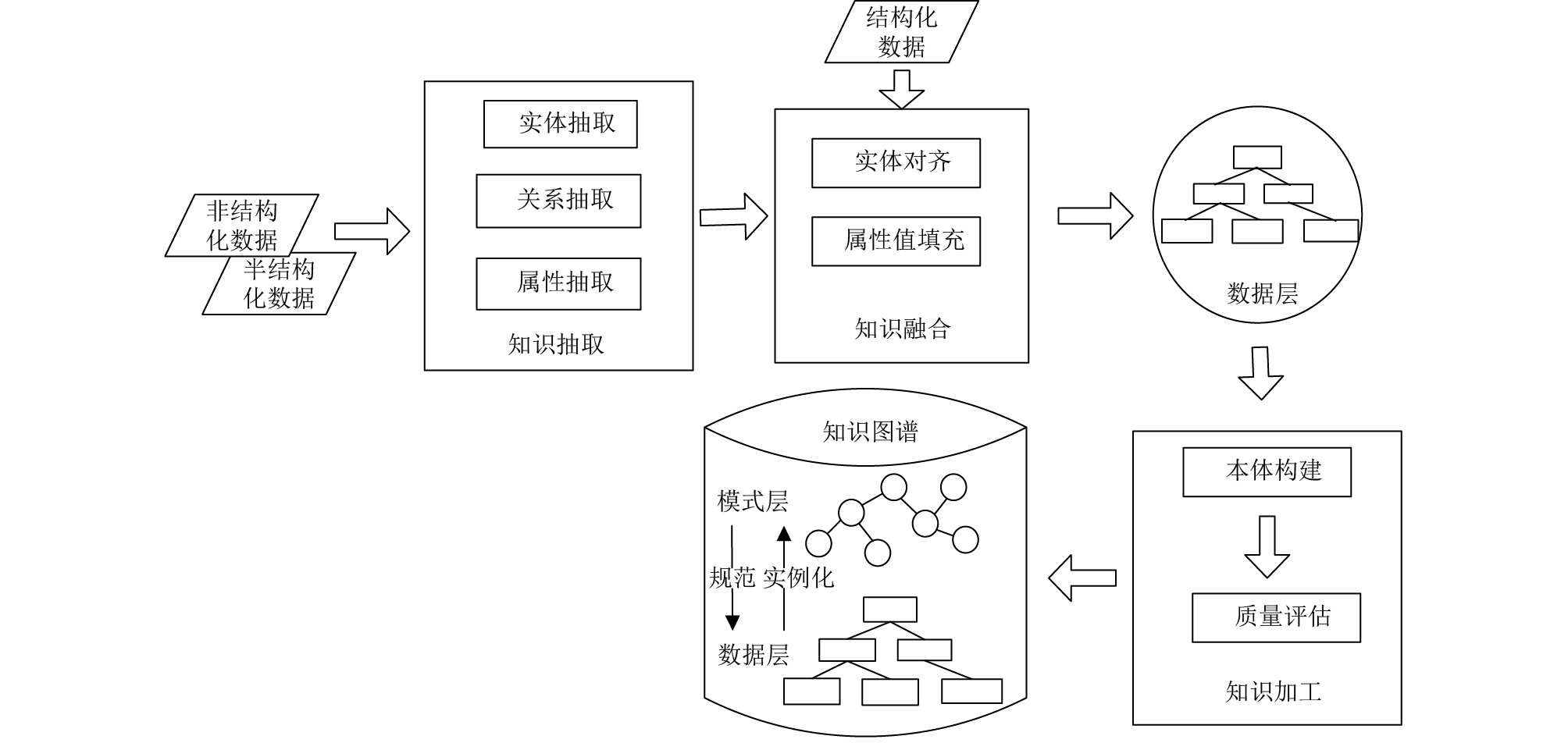
无论自顶而下还是自底而上的方法都需要解决以下三个问题:
- 模式层的定义:数据模式的定义包括类 (本体) 的定义及类 (本体) 的约束。由于类 (本体) 之间存在上下位关系,而类 (本体) 的约束依赖于属性的定义,因此数据模式的定义依赖于关系的设计或抽取。
- 实体连接的设计/抽取:实体连接分为分类实体连接和非分类实体连接,分类实体连接即本体的上下位关系与本体和实体的分类关系,非分类实体连接即除了分类实体连接以外其他的实体连接,通常对应本体中的属性或关系,主要是自然语言中的动词和描述性的词语。
- 分类实体连接的设计或抽取。通常采用的方法有:基于词法模式的方法,基于共现分析的方法,基于语言学的方法和基于开发链接数据和在线百科的方法。
- 非分类实体连接的设计或抽取。通常采用的方法有:基于关联规则分析的方法和基于开发链接数据和在线百科的方法。
- 当前的知识图谱构建技术中,主要从结构化和半结构化的数据中抽取实体和关系,且在抽取到分类关系或非分类关系后,没有利用关系对类进行约束,从而不能利用类的约束从非结构化的文本中抽取实例。
- 数据层的学习:实体是知识图谱中的主要组成部分,实体层的学习包括实体的词汇实现和实体的数据填充。实体的词汇实现是指表述实体的词汇,通常对应文章页面的标题。实体的数据填充主要为实体添加属性及属性值,或者通过属性建立实体与其他实体之间的关系。
4、知识图谱的相关技术
我们以该图为例,来简单介绍构建知识图谱可能所需的一些方法和技术;注意,以下技术仅仅作为介绍了解,并不要求大家一一掌握;而构建一个简单的领域知识图谱,并不需要涉及到这其中提到的所有技术,只需掌握具体思路,在自己的项目上按情况学习选用即可。
4.1 领域数据
一般来说,领域原始知识往往有各种不同的数据表现形式
-
结构化数据:结构化数据,可以从名称中看出,是高度组织和整齐格式化的数据。结构化数据可以轻易放入表格和电子表格中的数据类型,典型的比如使用关系型数据库表示和存储,表现为二维形式的数据。一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。如:
1 Liu Yi 20 male 2 Chen Er 35 female 3 Zhang San 28 male典型的结构化数据包括关系数据库数据等。
-
半结构化数据:半结构化数据是结构化数据的一种形式,它并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用来分隔语义元素以及对记录和字段进行分层。半结构化数据,属于同一类实体可以有不同的属性,即使他们被组合在一起,这些属性的顺序并不重要。
典型的半结构数据有 XML 和 JSON,对于对于两个 XML 文件,第一个可能为:
<person> <name>A</name> <age>13</age> <gender>female</gender> </person></pre>第二个可能为:
<person> <gender>male</gender> <name>B</name> </person></pre>通过这样的数据格式,可以自由地表达很多有用的信息,包括自我描述信息 (元数据)。
-
非结构化数据:非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。典型的非结构化数据,包括所有格式的办公文档、文本、图片、各类报表、图像和音频/视频信息等等。如以下文本:
天津大学 (Tianjin University),创办于1895年,简称 “天大”,坐落于天津市,是中华人民共和国教育部直属的首批全国重点大学,是国家 “双一流” 建设高校、国家 “211 工程” 和 “985 工程” 建设高校,中国工程院和教育部 10 所工程教育改革试点高校之一,与南开大学为兄弟院校……
领域数据,我们首先要解决的是其来源问题。
- 结构化数据:这类数据最为干净规整,但是也较难获得,可以通过寻找领域内开源数据集来获取结构化数据。
- 半结构化数据:这类数据较为规整,但需要进一步收集和处理,可以通过爬虫技术在合法合规的前提下进行爬取。
- 非结构化数据:这类数据最为复杂,形态最为多样。较为有效的方式是确定实体后,使用爬虫技术爬取该主题对应的内容;如法律法规的原文、新闻事件的报道、报告的文本图片等等。
4.2 信息抽取
在有了原始数据之后,我们需要解决的问题是如何从不同的数据源中抽取出结构规范的知识 (这里所谓的只是结构就是我们在上文中所提到的 “本体 “)。
- 对于结构化数据,只需将结构化数据与已有的知识库的 Schema 进行对应,简单合并即可;
- 对于非结构化或半结构化数据,需要通过人工或者自动方式抽取规范化知识。
信息抽取就是为了解决在非结构化或半结构化数据中准确获得规范的实体、关系、属性而提出的。信息抽取涵盖三个方面的需要:
-
实体抽取:实体抽取又称为命名实体识别 (named entity recognition,NER),是指从文本数据集中自动识别出命名实体。

-
关系抽取:文本语料经过实体抽取之后,得到的是一系列离散的命名实体。为了得到语义信息,还需要从相关语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。
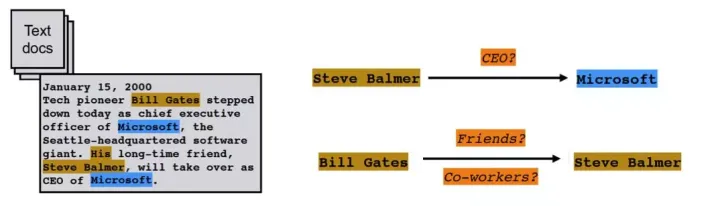
-
属性抽取:属性抽取的目标是从不同信息源中抽取特定实体的属性信息,如针对某个公众人物,可以从网络公开百科数据中抽取其昵称、生日、国籍、教育背景等信息。属性抽取技术能够从多种数据来源中汇集这些信息,实现对实体属性的完整勾画。
在信息抽取阶段,使用的技术主要有两种思路:
- 众包抽取:通过众包编辑工具对半结构化或非结构化数据进行人工 “打标签”,通过众包方式来获得准确的信息抽取。
- 自动化抽取:通过对非结构化数据进行自动化处理。
- 基于规则的方法:依靠手工编写的正则表达式/词典、规则,来识别文本中的实体、关系和属性。
- 基于统计的方法:基于大规模标注语料库,训练统计模型,如 HMM、CRF 等。
- 基于深度学习的方法:使用神经网络模型,如 Bert,RNN、LSTM、CNN 等。
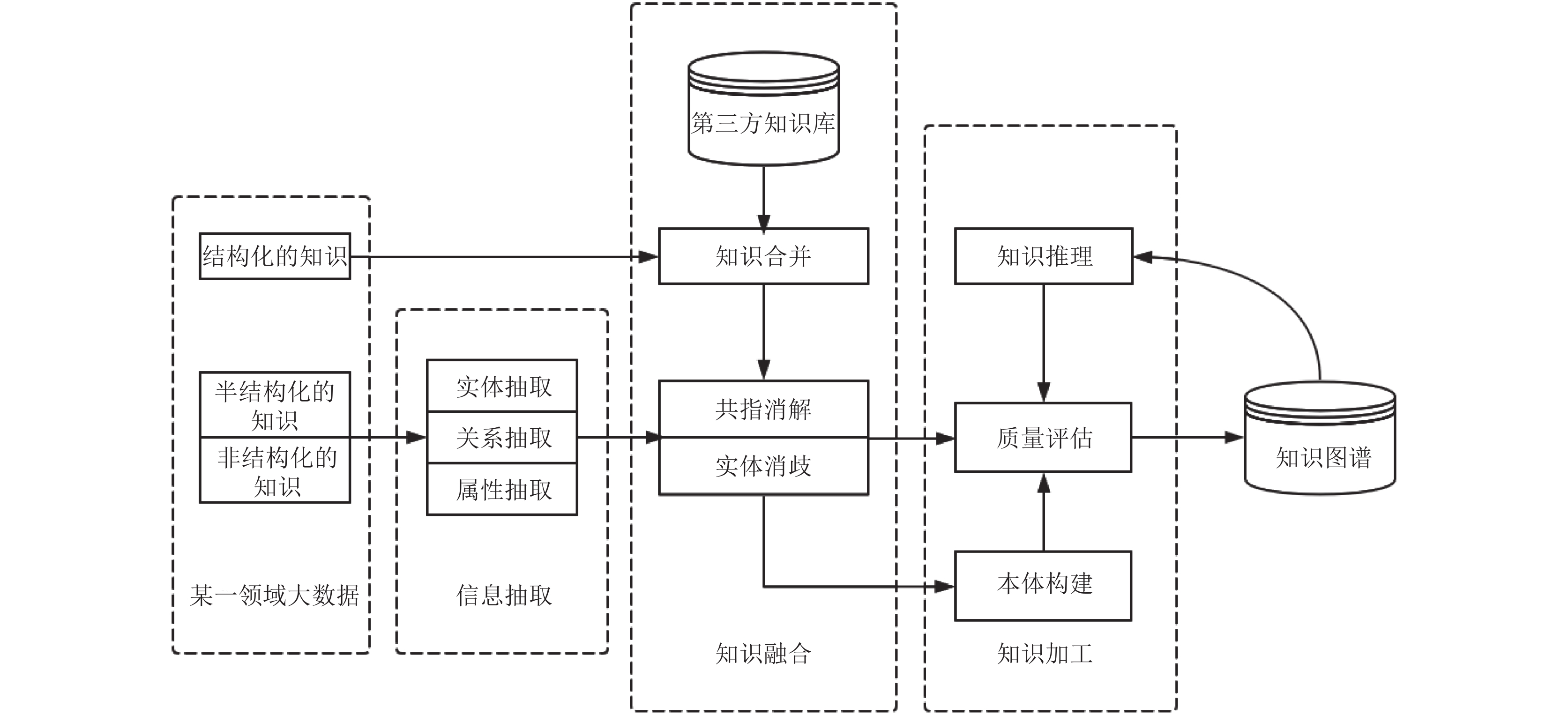
4.3 知识融合
通过信息抽取,我们就从原始的非结构化和半结构化数据中获取到了实体、关系以及实体的属性信息。如果我们将接下来的过程比喻成拼图的话,那么这些信息就是拼图碎片,散乱无章甚至还有从其他拼图里跑来的碎片、本身就是用来干扰我们拼图的错误碎片。也就是说,拼图碎片 (信息) 之间的关系是扁平化的,缺乏层次性和逻辑性;拼图 (知识) 中还存在大量冗杂和错误的拼图碎片 (信息)。那么如何解决这一问题,就是在知识融合这一步里我们需要做的了。
知识融合包括 2 部分内容:实体链接、知识合并。
4.3.1 实体链接
实体链接 (entity linking) 是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。其基本思想是首先根据给定的实体指称项,从知识库中选出一组候选实体对象,然后通过相似度计算将指称项链接到正确的实体对象。
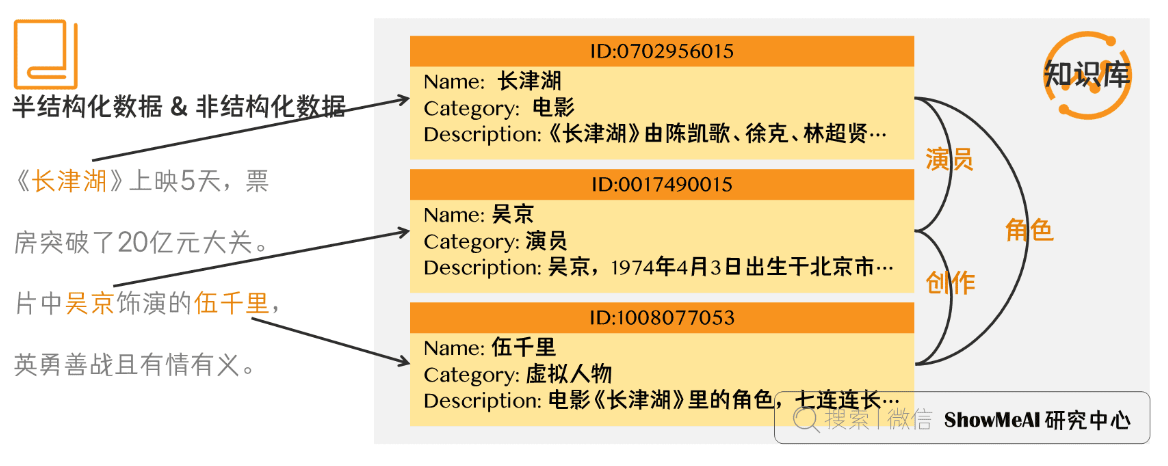
实体链接的流程:
- 从文本中通过实体抽取得到实体指称项。
- 进行实体消歧和共指消解,判断知识库中的同名实体与之是否代表不同的含义以及知识库中是否存在其他命名实体与之表示相同的含义。
- 在确认知识库中对应的正确实体对象之后,将该实体指称项链接到知识库中对应实体。
实体消歧:是专门用于解决同名实体产生歧义问题的技术,通过实体消歧,就可以根据当前的语境,准确建立实体链接,实体消歧主要采用聚类法。其实也可以看做基于上下文的分类问题,类似于词性消歧和词义消歧。
共指消解:主要用于解决多个指称对应同一实体对象的问题。在一次会话中,多个指称可能指向的是同一实体对象。利用共指消解技术,可以将这些指称项关联 (合并) 到正确的实体对象,由于该问题在信息检索和自然语言处理等领域具有特殊的重要性,吸引了大量的研究努力。共指消解还有一些其他的名字,比如对象对齐、实体匹配和实体同义。
4.3.2 知识合并
在前面的实体链接中,我们已经将实体链接到知识库中对应的正确实体对象那里去了,但需要注意的是,实体链接链接的是我们从半结构化数据和非结构化数据那里通过信息抽取提取出来的数据。那么除了半结构化数据和非结构化数据以外,我们还有个更干净规整的数据来源———结构化数据,如外部知识库和关系数据库。
一般来说知识融合主要分为两种:合并外部知识库,主要处理数据层和模式层的冲突;合并关系数据库,有 RDB2RDF 等方法。
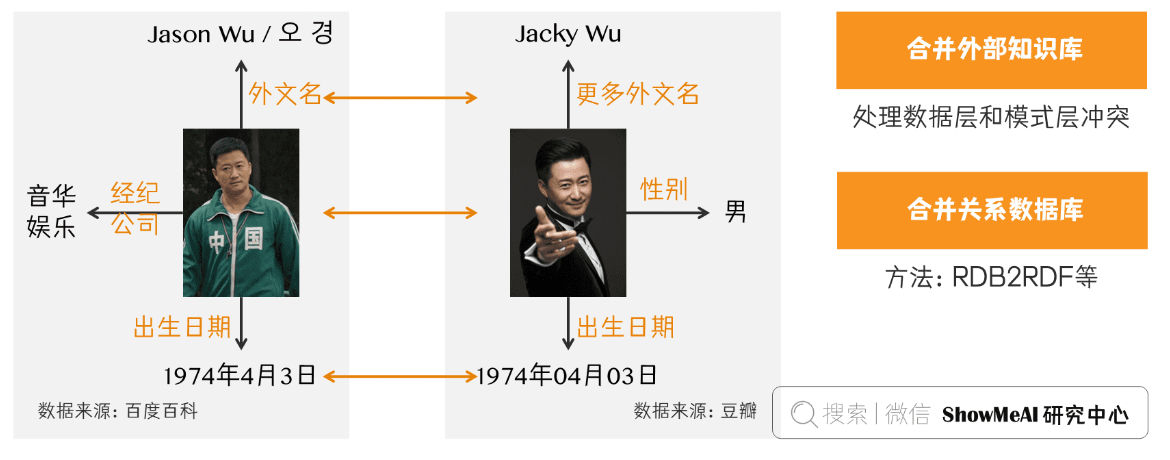
在我们的 Semantic MediaWiki 的知识图谱实践中,我们利用 MediaWiki 的模板和表单机制来进行自动化的知识合并。
4.4 知识加工
知识加工主要包括本体构建、知识推理、质量评估三个方面的技术;
-
本体构建:如上所述,在本体构建中有自顶向下和自底向上两种方案。这里不再赘述。
-
知识推理:在我们完成了本体构建这一步之后,一个知识图谱的雏形便已经搭建好了。但可能在这个时候,知识图谱中一些关系是残缺的不充分的,那么这个时候,我们就可以使用知识推理技术,去完成进一步的知识发现。当然知识推理的对象也并不局限于实体间的关系,也可以是实体的属性值,本体的概念层次关系等。
- 推理属性值:已知某实体的生日属性,可以通过推理得到该实体的年龄属性;
- 推理概念:已知 (老虎,科,猫科) 和 (猫科,目,食肉目) 可以推出 (老虎,目,食肉目)
这一块的算法主要可以分为 3 大类:基于知识表达的关系推理技术;基于概率图模型的关系推理技术路线示意图;基于深度学习的关系推理技术。
-
质量评估:质量评估也是知识库构建技术的重要组成部分,这一部分存在的意义在于:可以对知识的可信度进行量化,通过舍弃置信度较低的知识来保障知识库的质量。
二、Semantic MediaWiki 下的知识图谱构建方案
1、知识图谱与 SMW 的要素对应关系
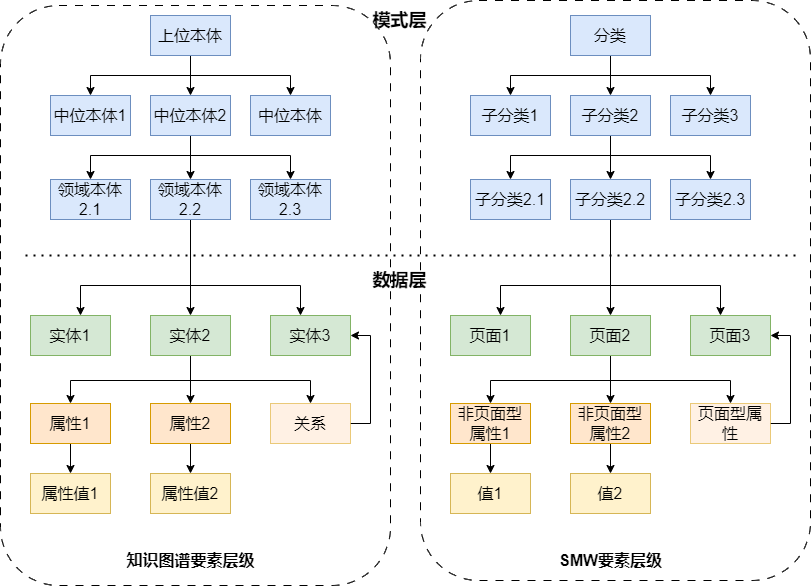
上图非常重要,它解释了我们是如何在 Semantic MediaWiki 中构建知识图谱的。回顾我们上一章与这一章的内容,我们会发现之前所介绍的 SMW 的一些要素 (如页面、分类、属性等) 与知识图谱中的要素有着比较一致的对应关系。
| 知识图谱要素 | SMW要素 | Wiki平台示例 |
|---|---|---|
| 本体 | 分类 | “分类:大学”页面 |
| 本体树 | 分类树 | “分类:大学”页面属于“分类:机构“页面 |
| 实体 | 页面 | “天津大学”页面 |
| 关系 | 页面型属性 | “属性:兄弟院校” |
| 属性 | 非页面型属性 | “属性:创办时间” |
| 属性值 | 值 | 1895 |
另外 Semantic MediaWiki 平台还给出了一系列工具和特性来支持语义化,如语义查询、RDF 导出、RDF 后端存储等。因此,我们可以在 SMW 平台上实现我们的知识图谱的基本构想。不过,Semantic MediaWiki 的 “分类” 体系是相当松散的,仅仅能实现层次化的分类关系,并不能指定分类所对应的属性。因此在本体构建 (Schema 设计) 方面,我们还需要对 Semantic MediaWiki 的分类体系进行扩展。我们会在本文后面介绍在 SMW 上进行扩展和 Schema 设计的流程。
2、SMW 下知识图谱构建流程
下面我们来简单介绍一下 SMW 下的行业知识图谱构建大致流程。
- 第一步,本体构建:针对目标领域,使用本体构建软件 (Protege) 来构建本体模型生成 OWL,或者使用传统 UML 来构建 Schema 结构。
- 第二步,SMW 下的 Schema 构建:根据已经创建好的本体模型,在 SMW 下创建具体的 Schema 结构:
- 创建分类,定义分类所具有的属性与分类层次结构;
- 创建属性,定义属性名、属性类型、属性描述与约束;
- 创建模板,定义页面所具有的数据、页面结构与外观展示样式;
- 创建表单,定义众包编辑所需的表单项;
- 第三步,数据获取:根据定义好的本体模型 (Schema 结构) 来寻找合适的开源数据集或进行数据爬取。
- 第四步,信息抽取 (可选):对爬取到的数据进行分词、实体抽取、关系抽取、属性抽取等。
- 第五步,知识融合导入:将数据进行指代消解、实体消歧等,使用脚本将数据对应到 SMW 的模板项中,自动化导入至 Wiki 平台。
- 第六步,知识标注:对导入的文本进行众包标注,增强数据的准确性和内容量。
- 第七步,图谱应用:对知识库进行知识图谱的可视化,并进行简单的语义检索。
三、Semantic MediaWiki 下的知识图谱 Schema 设计
一般来说,在 SMW 下构建知识图谱的步骤中,构建 Schema 是较为困难,缺乏简易替代的难点任务;而数据本身的爬取、整理、信息抽取乃至数据导入都有开源的、即开即用的方法,可以自行探索;而 SMW 本身就能实现一些简单的图谱上语义检索、查询、可视化的应用。因此 Schema 设计是重点章节,需要我们进行特别的强调:本体构建 (或 Schema 设计) 是数据层知识图谱的基础,要保证 Schema 设计的合理、全面、有意义,才能保证知识图谱本身的可用性。
本体设计的难点不在于技术本身,我们这里提供了一系列工具和扩展来方便我们的 Schema 设计任务;本体设计的难点体现在:
- 对领域或行业知识的深入理解:比如我们想要设计一个农业领域的行业知识图谱,需要我们对农业领域的一系列技术、概念、术语、实体都有深入的了解,才能保证本体构建的合理性;
- 对本体、属性的约束定义:在进行 Schema 设计时,需要谨慎设计属性名、属性的约束、属性所对应的分类等;这些需要通过不断实践和修改才能最终确定。
1、Protege 本体设计
培训资源:
- 教程教程:教程文件夹下的
Protege教程.pdf文件,感谢王永峰,卢培铭,谢云飞三位同学。 - 培训视频链接:https://meeting.tencent.com/v2/cloud-record/share?id=4693d81a-f7ee-4fac-91ce-d06f9d9b1e7b&from=3
建议参考文档:
- Protégé 基本教程:https://blog.csdn.net/Jenny_oxaza/article/details/83148300
- OWL 本体构建指南:https://zhuanlan.zhihu.com/p/136570668
- 斯坦福本体设计七步法:
2、UML 设计
培训资源:
- 教程文档:教程文件夹下的
UML图的概念、方法与使用工具.docx文件,感谢陈市,袁健铭,李心怡三位同学。 - 培训视频链接:https://meeting.tencent.com/v2/cloud-record/share?id=4693d81a-f7ee-4fac-91ce-d06f9d9b1e7b&from=3
建议参考文档:
- 30分钟学会 UML 类图:https://zhuanlan.zhihu.com/p/109655171
3、SMW 本体设计
3.0 前提条件
在进行分类扩展之前,请检查 Wiki 的版本页,查看是否有以下三个插件。如果没有,需要进行插件安装。
-
安装 Widgets 插件:https://www.mediawiki.org/wiki/Extension:Widgets
- 注意安装 Widgets 插件,需要修改 extension 文件夹下,Widgets 文件夹中的 compiled_templates 的读写权限。特别是 Linux 系统下安装的 MediaWiki 平台更需如此。
- 参考:https://www.mediawiki.org/wiki/Extension:Widgets#Installation
- 参考:https://web.archive.org/web/20160417115203/http://www.g-loaded.eu/2008/12/09/making-a-directory-writable-by-the-webserver/
-
安装 TemplateStyles 插件:https://www.mediawiki.org/wiki/Extension:TemplateStyles
-
安装 NoTitle 插件:https://www.mediawiki.org/wiki/Extension:NoTitle
-
安装MagicNoCache插件:https://www.mediawiki.org/wiki/Extension:MagicNoCache
-
注释掉 SyntaxHighlight_GeSHi 语法高亮插件,在
Localsettings.php文件中,将:wfLoadExtension( 'SyntaxHighlight_GeSHi' );注释为:
# wfLoadExtension( 'SyntaxHighlight_GeSHi' );
3.1 Semantic MediaWiki 分类扩展导入
由于 Semantic MediaWiki 本身的分类体系约束较弱,很难确定一个分类所对应的属性、模板、表单等。因此我们需要对 Semantic MediaWiki 本身的分类体系进行扩展;我们在之前已经独立开发设计了分类扩展插件,只需简单导入即可使用。
第一步:在特殊页面,找到页面工具-导入页面。
第二步:选择教程文件夹中的 SMW分类扩展.xml 文件,并在跨 wiki 前缀中填入 “wiki”,点击 “上传文件”。
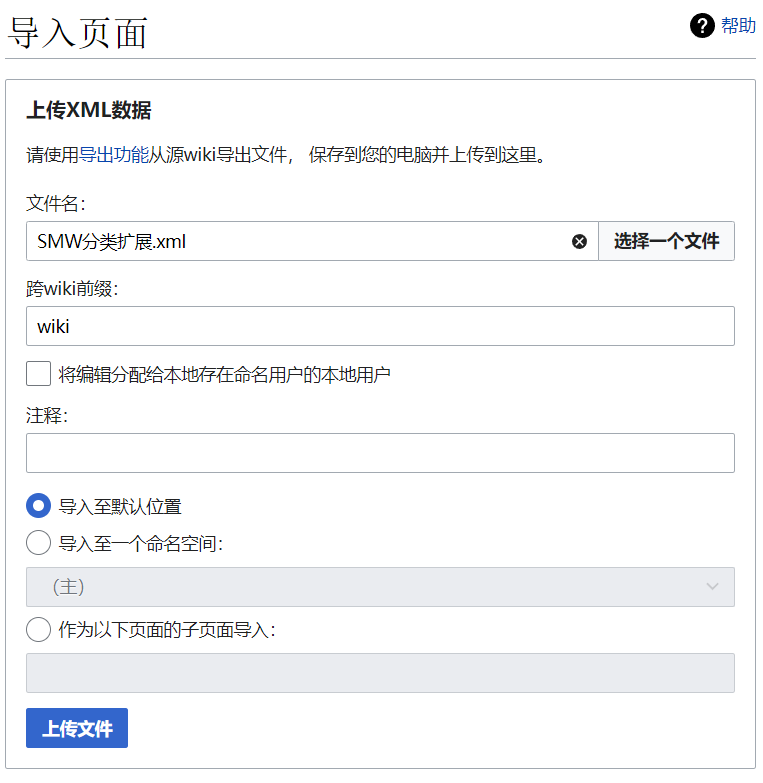
第三步:导入需要等待一段时间,没有红色报错即说明导入扩展完成。

第四步:最后,在 mediawiki 根目录下,运行命令行,输入并运行以下命令:
php maintenance/runJobs.php
3.2 利用分类扩展来创建 Schema
下面我们将介绍如何利用分类扩展来设计 Schema,我们这里利用分类扩展,创建三个分类 (本体),分别是:学校、大学、院士。
第一步:在特殊页面 “表单” 中找到 “Schema 定义” 表单。或者直接访问链接:
http://localhost/mediawiki/index.php/Form:Schema%E5%AE%9A%E4%B9%89
第二步:使用 “Schema 定义” 表单,创建页面 分类:学校 (注意使用英文冒号)。或者直接访问链接:
http://localhost/mediawiki/index.php/Special:%E7%BC%96%E8%BE%91%E8%A1%A8%E6%A0%BC/Schema%E5%AE%9A%E4%B9%89/%E5%88%86%E7%B1%BB:%E5%AD%A6%E6%A0%A1
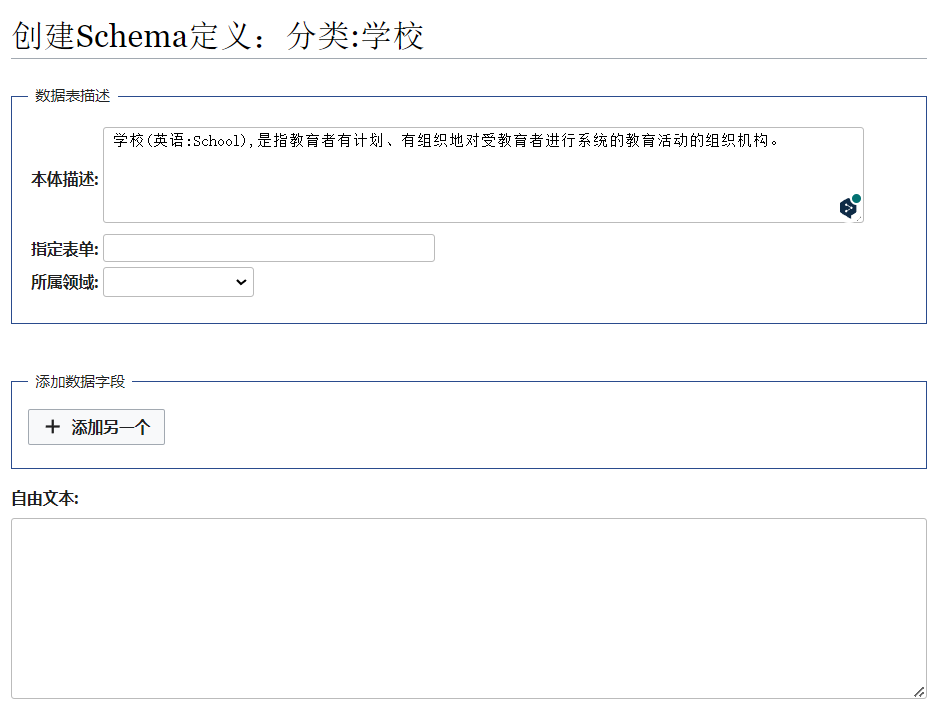
- 本体描述:用来简单介绍或描述 “学校” 这一分类的主要内容;
- 指定表单:用来指定创建 “学校” 这一分类 (本体) 对应的页面 (实体) 所用的表单。举例来说,“天津大学” 页面 (实体) 属于 “大学” 分类 (本体),因此应当在定义大学这一分类 (本体) 时指定创建 “天津大学” 页面的表单,如 “表单:大学信息框”。可以为空。
- 所属领域:用来指定当前本体属于哪一领域。可以为空。
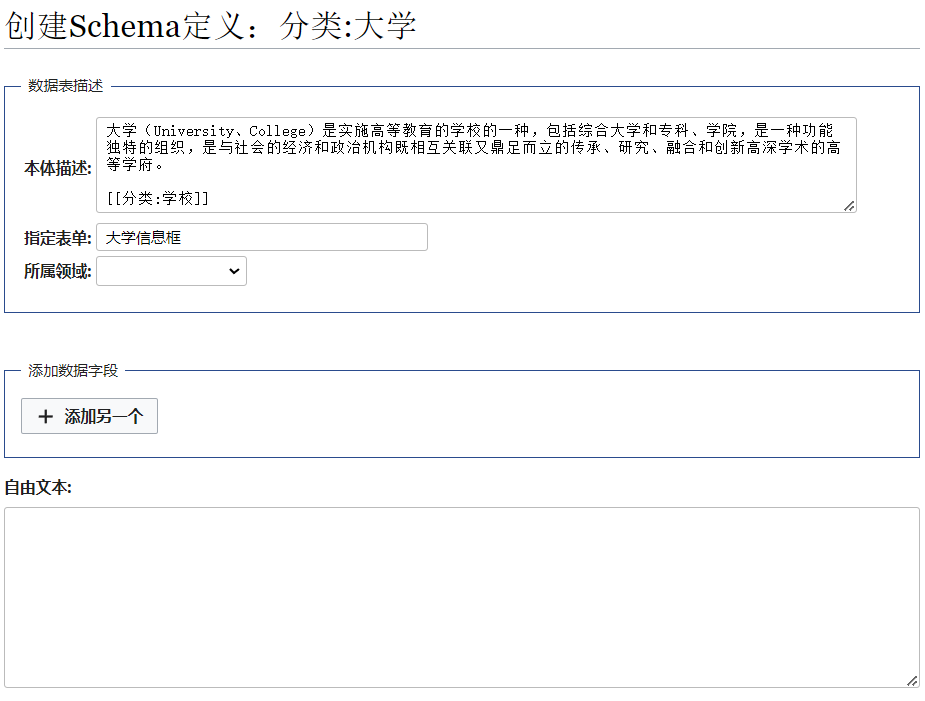
类似地,使用 “Schema 定义” 表单,创建页面 分类:大学。注意,由于”学校 “与” 大学 “存在概念上的继承关系,因此我们应当在” 大学 “的本体描述中,指定” 大学 “的分类为” 学校 “。
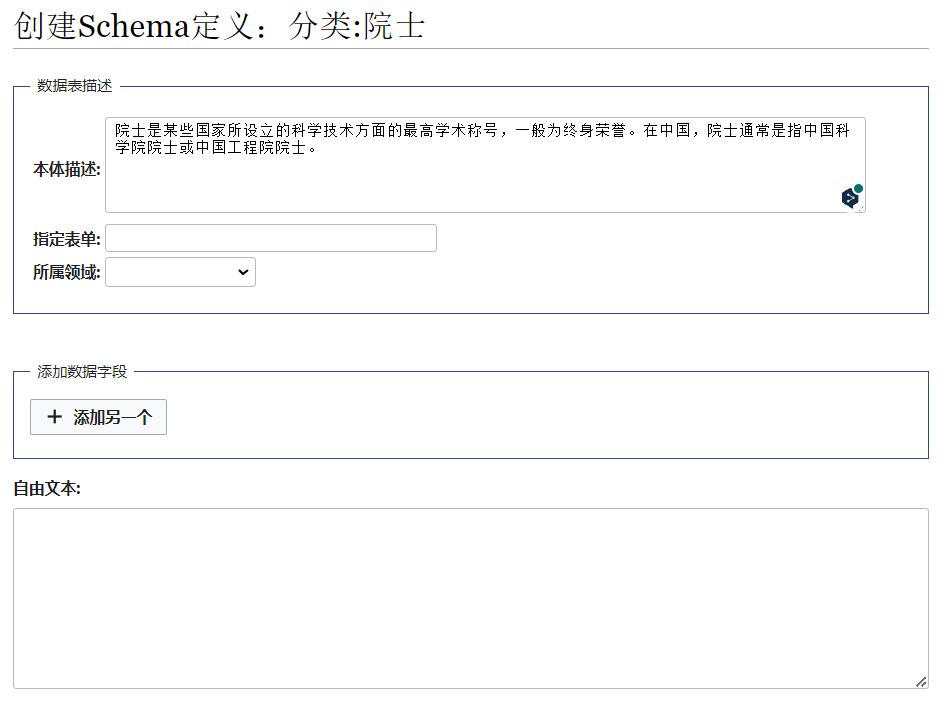
类似地,使用 “Schema 定义” 表单,创建页面 分类:院士。
第三步:在 mediawiki 根目录下,运行命令行,输入并运行以下命令:
php maintenance/runJobs.php
第四步:为学校、大学、院士添加属性关系字段。访问页面 “分类:学校”,点击 “表单编辑”
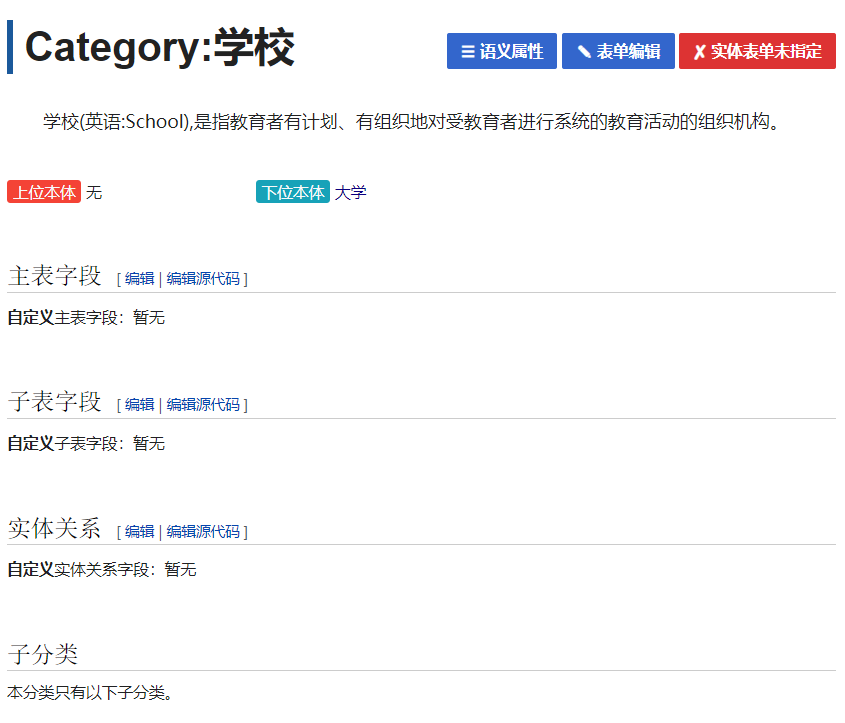
选择添加数据字段:
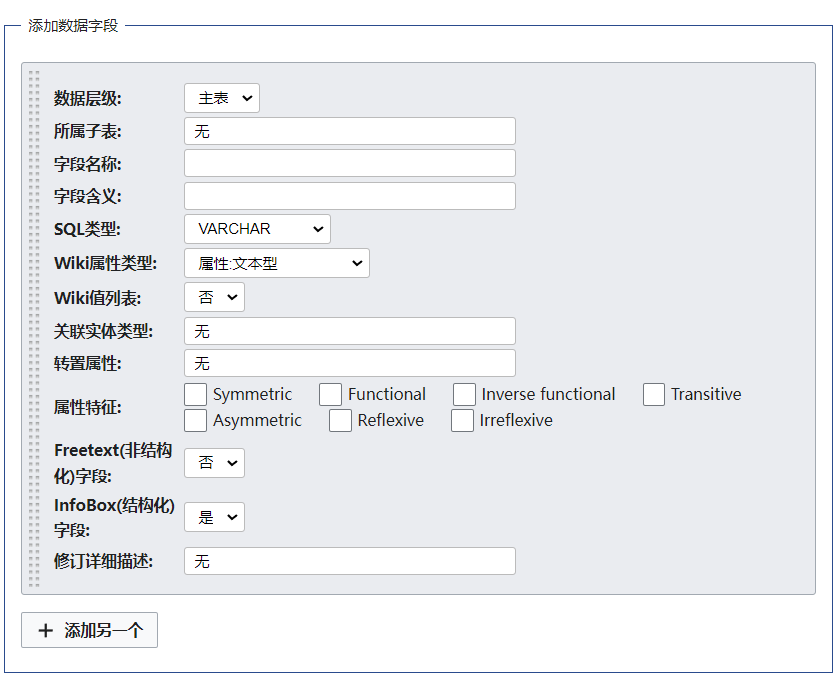
- 数据层级:默认为主表,主表指的是当前本体本身,所具有的主要属性或关系。比如 “汽车” 本体具有 “生产厂商”,“变速器型号”,“排量” 等属性或关系;而子表指的是与当前本体具有 “组合” 关系等强耦合关系的子实体,所具有的属性或关系。如 “汽车轮胎” 与 “汽车” 具有组合关系,它本身还具有 “生产厂商”,“零售价” 等属性或关系。当然,这里的 “子表” 仅仅是一种简化的本体概念,它本身也可以抽离出来独立作为一个单独的本体存在。
- 所属子表:默认为无,在数据层级为子表时,才使用该项,可以用来指定当前字段属于哪个子表,如 “汽车轮胎” 子表或 “汽车发动机” 子表。
- 字段名称:指定当前数据字段的名称。一般使用英文命名,建议使用大驼峰命名法 (帕斯卡命名法)。如该字段是”变速器型号 “字段,应当命名为:TransmissionModel。不可为空。
- 字段含义:指定当前数据字段的含义。一般使用中文,解释应当言简意赅。如该字段是”变速器型号 “字段,其含义为:“指汽车厂家提供的由字母数字组成的名称编号,指定变速器的一系列性质”。不可为空。
- SQL 类型:默认为 VARCHAR 类型,指定当前字段在 SQL 中的存储类型。
- Wiki 属性类型:默认为文本型,指定当前字段在 Wiki 平台上的类型。**当选择为 “页面型” 时,当前字段为关系字段。**如 “汽车” 的 “生产厂商” 关系,在 “汽车” 本体与 “汽车制造企业” 本体之间建立了关系。
- Wiki 值列表:默认为否,用来指定当前字段是否会在本体中出现多次。例如 “汽车” 本体的 “排量” 属性,同一型号的汽车可能有多种排量。因此 “排量” 属性的 Wiki 值列表应当选 “是”。
- 关联实体类型:默认为无,在 Wiki 属性类型为页面型时,才使用该项。用来表示当前页面型属性 “指向” 的页面属于哪一分类 (本体)。举例来说,“特斯拉 Model Y 汽车” 页面的 “生产厂商” 属性,指向了 “特斯拉公司” 这一页面,而 “特斯拉公司” 这一页面又属于 “汽车制造企业” 这一本体。
- 转置属性:默认为无,指的是当前属性的 “反向” 属性。例如 “汽车” 本体的 “生产厂商” 属性,其转置属性对应了 “汽车制造企业” 本体的 “旗下车型” 属性 (这里的关系大家需要认真理解)。
- 属性特征:默认空选。对应了 Protege 中对属性约束。参看该文章 2.2 节对象属性的建立:https://blog.csdn.net/Jenny_oxaza/article/details/83148300
- Freetext (非结构化) 字段:默认否。如果该字段常常出现在文本中,需要人工打标签或众包标注,则称为非结构化字段。
- InfoBox (结构化) 字段:默认是。如果该字段的数据源比较规整,为结构化数据,无需手动处理,则为结构化字段。
- 修订详细描述:默认无。用来记录对当前字段的修改情况。
下面我们为 “学校” 本体添加四个属性:学校名称、创办时间、学校位置、兄弟院校,字段设置如下:

注意,设置字段后不会马上显示在分类页,后台会进行一系列处理。如果想直接看到更新,可以在浏览器的地址栏末尾加上 ?action=purge,手动刷新缓存。
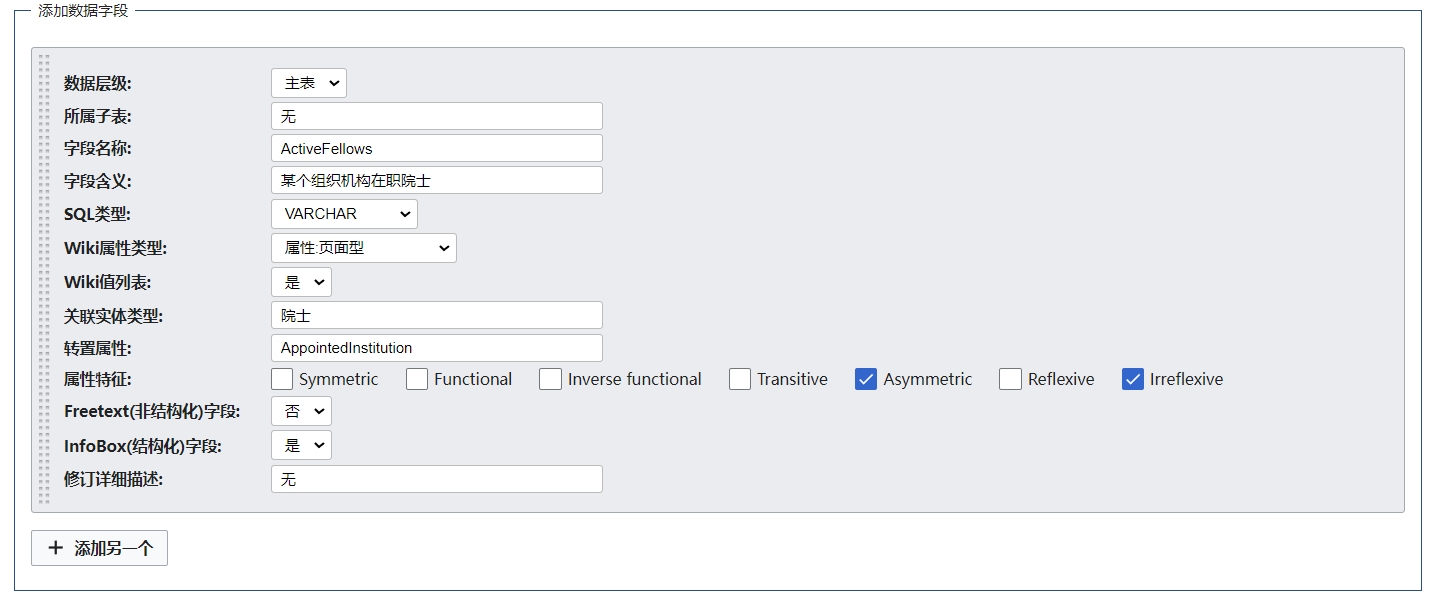
类似地,我们为 “大学” 本体添加一个属性:在职院士,字段设置如下:
类似地,我们为 “院士” 本体添加三个属性:姓名,在职机构,母校

第五步,设置完成,检查页面。
四、作业安排
本周的内容以阅读、理解为主,主要向大家介绍了知识图谱的基础知识,包括了概念、分类、组成架构、构建方案以及相关技术等。同时也跟大家初步介绍了我们在 SMW 上建立知识图谱的基本思路的主要方法。同时我们对 SMW 进行了扩展,以适应实践中的本体设计任务。大家可能对于知识图谱的实际建立流程依然存在疑惑,下周我们将以 “中国院士” 为主题,在 MediaWiki 上建立一个以知识库为基础的小型领域知识图谱。
本周作业:
-
任务 1:浏览、学习基本的 CSS 语法,并用 HTML 语言 + CSS 修改原有的天津大学的百科介绍页面 (两周任务)
-
任务 2:实操
-
安装 Widgets 插件:https://www.mediawiki.org/wiki/Extension:Widgets
- 注意安装 Widgets 插件,需要修改 extension 文件夹下,Widgets 文件夹中的 compiled_templates 的读写权限。特别是 Linux 系统下安装的 MediaWiki 平台更需如此。
- 参考:https://www.mediawiki.org/wiki/Extension:Widgets#Installation
- 参考:https://web.archive.org/web/20160417115203/http://www.g-loaded.eu/2008/12/09/making-a-directory-writable-by-the-webserver/
-
安装 TemplateStyles 插件:https://www.mediawiki.org/wiki/Extension:TemplateStyles
-
安装 NoTitle 插件:https://www.mediawiki.org/wiki/Extension:NoTitle
-
注释掉 SyntaxHighlight_GeSHi 语法高亮插件,在
Localsettings.php文件中,将:wfLoadExtension( 'SyntaxHighlight_GeSHi' );注释为:
# wfLoadExtension( 'SyntaxHighlight_GeSHi' );
-
-
任务 3:为 “机构”、”学校 “、“大学”、“院士”、“论文” 五个本体进行 Schema 设计
- 使用 Protege 或 UML 进行本体设计。
- 在 Wiki 平台上,使用分类扩展来创建 Schema。
- 分别为 “大学”、“院士”、“论文” 建立表单,并在分类扩展中指定。
- 要求:“机构”、”学校 “、“大学” 属性不少于 7 个,“院士”、“论文” 属性不少于 10 个;需要定义清晰属性特征和转置属性。
Last modified on 2023-11-05